CyberSpace CTF 2024 - shop
Table of Contents
0x00. Introduction
Concept
>
Using buy_143A(), we allocate heap chunks and store the allocated address and size. These are stored in globally declared void *ptr_4060[32] and int size_4160[32].
In edit_1523(), we input an index to modify the contents of the chunk stored in ptr_4060[index].
Similarly, in refund_15F6(), we input an index to free the chunk stored in ptr_4060[index].
Note that read_flag_12A9() reads the flag and stores it in the heap, so we don’t need to get shell.
0x01. Vulnerability
int
refund_15F6() verifies that ptr_4060[index] is not NULL and frees ptr.
It sets size_4160[index] to 0 afterward but doesn’t nullify ptr_4060[index], causing UAF vulnerability.
0x02. Exploit
Fastbin Reverse Into Tcache
While possible in older glibc versions (<=2.26), glibc 2.31 in the current docker environment has mitigation applied to prevent double free in tcache.
> 3
> 3
> 3
To bypass this, I used the fastbin reverse into tcache technique, referencing these resources:
These resources assume we can free a victim chunk and write values, but since edit is impossible when size_4160[index] is 0 in this challenge, we need to additionally create a fastbin dup situation.
The exploitation flow is as follows.
- Free
7fastbin-length chunks to fill tcache - Create fastbin dup using UAF
- Allocate
7chunks to empty tcache - Allocate
8th chunk to manipulatenext_chunk - Request chunk allocation until manipulated
next_chunkaddress is allocated - Use allocated address for AAW
Writing the payload step by step:
# fill tcache 0x20
# fastbin dup 8 -> 9 -> 8
Executing refund 7 times fills tcache, sending subsequent chunks to fastbin. Using this, we create an 8 -> 9 -> 8 loop in fastbin.
# clean tacahe 0x20
# partially overwrite next_chunk
After emptying tcache by executing buy 7 times, executing buy once more returns the 8th chunk. Since this 8th chunk stored size in size_4160[8] during buy, edit is possible.
Since we haven’t leaked heap yet, we can only partial overwrite lower bytes for probabilistic heap manipulation.
Tcachebins[idx=0, size=0x20, count=3] | | )
| | )
| | )
The \x40\x96 passed to edit partially overwrites the chunk’s next_chunk to manipulate the tcache list.
Looking closely, 0x555555559640 comes at the end of the tcache list. Although its size is 0, tcache doesn’t verify size during allocation, so the manipulated next_chunk gets allocated.
Come to think of it, carefully controlling size and position when allocating heap chunks to only overwrite one byte might enable exploitation without probability issues.
# allocate overwritten heap address
# index 11 ; overwritten heap address
# overwrite chunk size
As in the payload above, the partially overwritten address is returned during the 3rd buy, allowing us to modify values stored in heap.
Unsorted Bin Attack
To proceed further, the binary has no printing codes, making leaks impossible. Thinking about what we have, while we don’t know addresses, AAW is possible by manipulating next_chunk.
While pondering, I thought that just like partially overwriting the heap address stored in next_chunk earlier, if a libc address is stored there, we could partial overwrite to write somewhere in libc memory.
Getting a libc address into next_chunk can be accomplished with unsorted bin attack, but requires careful chunk overlapping. Illustrated as follows:
First, since we’ll ultimately perform AAW using chunks in fastbin, send sufficiently sized (0x60) chunks to fastbin. To send the victim chunk to unsorted bin, we need to carefully position intermediate chunks so the offset with next_chunk matches size.
Also, since next_chunk being top chunk merges with top chunk instead of going to unsorted bin, we need to consider this.
# fill tcache 0x70
# index 0 ; align next chunk
# 0x555555559650 chunk goes to fastbin
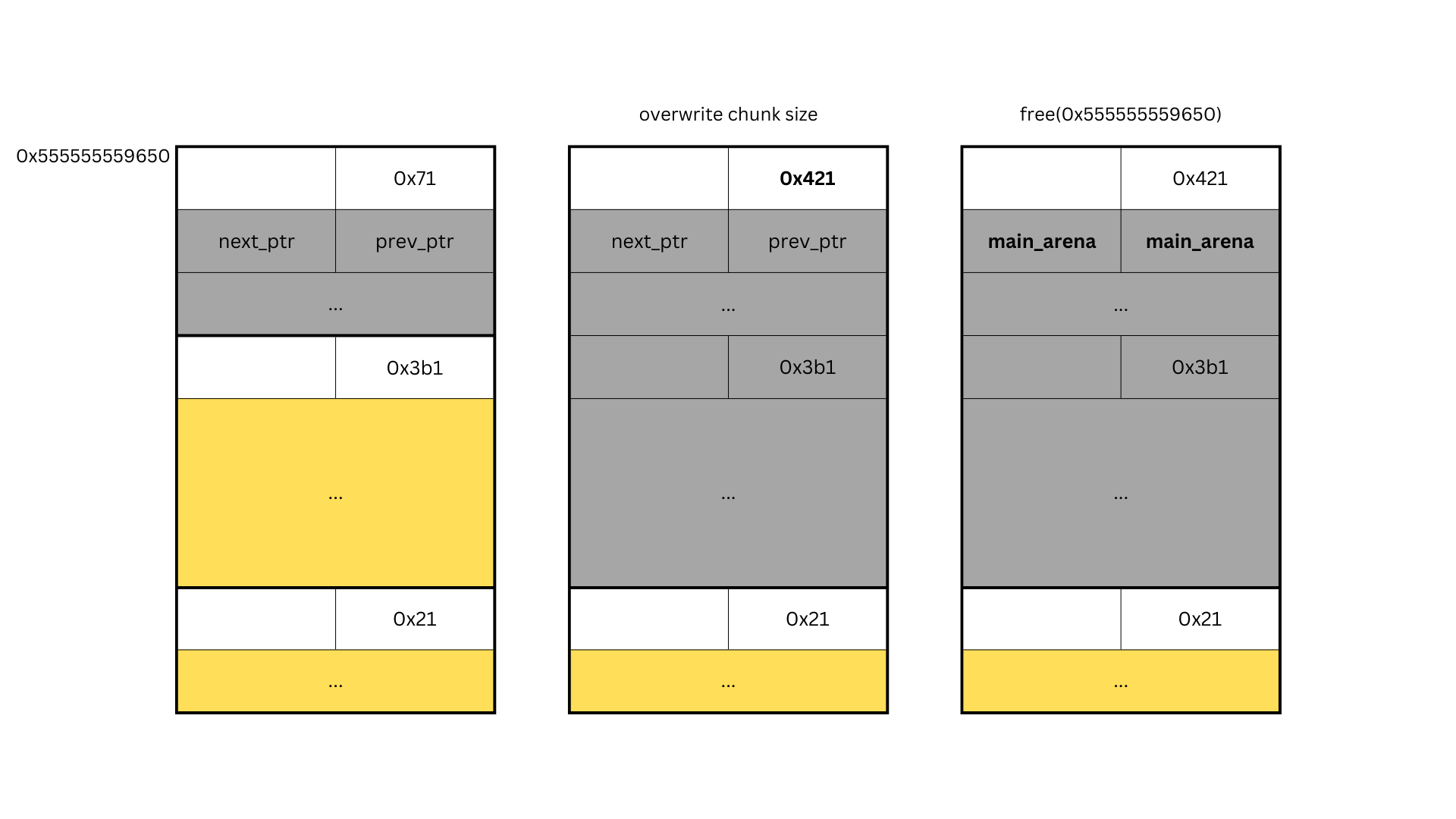
This sends the index 7 chunk (0x555555559650) to fastbin, and allocating a 0x3a0 chunk afterward creates the form in the first diagram.
Now to overwrite chunk size, we use the fastbin reverse into tcache technique.
# partially overwrite next_chunk
# allocate overwritten heap address
# index 11 ; overwritten heap address
# overwrite chunk size
Executing this payload creates the second diagram. We need to free the 0x555555559650 chunk, but there’s no pointer pointing to 0x555555559650. Since it’s an already freed chunk address, we can’t access it without allocating a 0x60-sized chunk again.
So we use the fastbin reverse into tcache technique once more to get that address returned.
# partially overwrite next_chunk
# allocate overwritten heap address
# index 15 ; overwritten heap address
# free(0x555555559650) ; move chunk to unsorted bin
This time, instead of editing the returned address, we refund to free it, creating the third diagram.
Fastbins[idx=5, size=0x70] | | )
| | )
| | )
Fastbins[idx=6, size=0x80]
| | )
Since the 0x555555559650 chunk remains in fastbin, main_arena in next_chunk is interpreted as the next chunk, enabling libc region allocation. However, fastbin verifies size, so we need to restore the chunk size overwritten to 0x421.
# restore chunk size
Stdout Attack
There’s a technique for libc leak when you can change stdout’s flag. I referenced this Korean resource:
After successfully performing unsorted bin attack, the main_arena address at 0x555555559650 is as follows.
Meanwhile, stdout points to an _IO_FILE structure stored in the libc region, with this address.
0x7ffff7fbfbe0 and 0x7ffff7fc06a0 differ by 3 bytes without ASLR, but occasionally differ by only 2 bytes with ASLR enabled, making exploitation possible with 1/16 probability when partial overwriting.
# partially overwrite main_arena -> stdout
# aslr off
# edit(s, 22, b"\xa0\x76") # aslr on
With 1/16 probability of allocating the libc address storing stdout’s _IO_FILE structure, we can change the flag to output libc addresses.
To summarize the exploit technique, when _IO_IS_APPENDING flag is on, _IO_new_do_write is called as follows, so we need to manipulate _IO_write_base and _IO_write_ptr.
// _IO_do_write (FILE *fp, const char *data, size_t to_do)
The status of _IO_FILE structure before manipulating is as follows.
The referenced resource overwrites the first byte of _IO_write_base with \x00, which would call _IO_do_write as follows.
// _IO_do_write (FILE *fp, const char *data, size_t to_do)
This output prints the libc address contained in the _IO_FILE structure.
# leak libc
= 0x1000
=
+= b * 0x19
=
Since libc leak is possible through this payload, areas like _IO_read_XXX don’t seem important for output.
Using this stdout structure enables AAR. Since the binary reads flag and stores it in heap memory, leaking the heap address lets us obtain the flag. Opposite to unsorted bin attack where we put main_arena address in next_chunk, main_arena contains heap addresses. Since main_arena is a variable stored in a fixed libc region, we calculate the offset and overwrite the value.
# leak heap - print main_arena
=
+= b * 0x18
+= # _IO_write_base
+= # _IO_write_ptr
+= # _IO_write_end
=
Note that output occurs when _IO_write_end equals _IO_write_ptr.
# print flag
=
+= b * 0x18
+= # _IO_write_base
+= # _IO_write_ptr
+= # _IO_write_end
=
After obtaining the heap address, we can obtain the flag with the payload above.
0x03. Payload
=
=
=
= 0x555555554000
=
= * 32
= 0
=
=
=
break
=
return
return
return
= f
=
=
=
=
=
=
=
# fill tcache 0x70
# index 0 ; align next chunk
# 0x555555559650 chunk goes to fastbin
# fill tcache 0x20
# fastbin dup 8 -> 9 -> 8
# clean tacahe 0x20
# partially overwrite next_chunk
# allocate overwritten heap address
# index 11 ; overwritten heap address
# overwrite chunk size
# fill tcache 0x20
# fastbin dup 12 -> 13 -> 12
# clean tcache 0x20
# partially overwrite next_chunk
# allocate overwritten heap address
# index 15 ; overwritten heap address
# free(0x555555559650) ; move chunk to unsorted bin
# clean tcache 0x70
# restore chunk size
# partially overwrite main_arena -> stdout
# aslr off
# edit(s, 22, b"\xa0\x76") # aslr on
# leak libc
= 0x1000
=
+= b * 0x19
=
= - 0x1ec980
= + 0x1ecbe0
# leak heap - print main_arena
=
+= b * 0x18
+= # _IO_write_base
+= # _IO_write_ptr
+= # _IO_write_end
=
= - 0xbc0
= + 0x308
# print flag
=
+= b * 0x18
+= # _IO_write_base
+= # _IO_write_ptr
+= # _IO_write_end
=
=
=
=
=